
Upgrading Recommender Systems with Large Language Models
Recommendations have become an indispensable part of our digital lives. From 'similar products' to 'customers who bought this also bought', personalized offers, and 'you may like' suggestions, these systems are more than mere features—they are the architects of our online experience. As the technology behind these recommendations evolves, its impact on user engagement, sales enhancement, and customer retention becomes ever more pronounced. For businesses, they are invaluable tools to boost revenue; for users, when fine-tuned, they offer a more personalized and enjoyable experience. Yet, there's a critical balance to strike: inaccurate recommendations can be more intrusive than helpful, cluttering our digital space with irrelevant content.
This is where the world of Large Language Models (LLMs) comes into play: These advanced AI systems are now being integrated into recommendation engines, heralding a new era in how we cater to and understand user preferences. With the sophisticated understanding capabilities of LLMs, recommendation systems are transcending the ordinary—they're evolving into intuitive guides, anticipating what users might love next.
In this article, we will delve into the recent advancements in recommendation systems, with a particular focus on the implementation of Large Language Models. How are industry leaders such as Microsoft and Google, redefining the landscape of recommendations? Join us as we explore this transformative journey
Traditional Approaches in Recommendation Systems
Before we dive into the revolutionary world of LLMs in recommendation systems, it's essential to appreciate the journey that has brought us here. Traditional models in recommendation systems laid the groundwork for today's advancements.

Collaborative Filtering
Picture a time when recommendations were based on the principle of 'neighbors know best.' Early models, like K-Nearest-Neighbor (KNN), made predictions by aligning user preferences with others like them. Although user-friendly and simple, these methods often stumbled when introduced to new users or vast datasets—a dilemma known as the 'cold start' problem.
Linear Models
To overcome some of these hurdles, linear models like logistic regression stepped in. They brought a sharper focus, factoring in additional information like user demographics and item attributes, thus enriching the recommendation experience. However, these models sometimes got bogged down in the complexity of feature engineering, struggling to capture the intricacies of user-item interactions.
Low-Rank Models
Enter low-rank models like Matrix Factorization, which streamlined datasets by distilling them into simpler forms. Efficient at handling basic interactions, they, however, found themselves outpaced when dealing with more complex user-item relationships.
Neural Models
The post-2016 era marked a seismic shift with the advent of deep neural network-based models. These models revolutionized recommendation systems, employing multi-layer architectures that delved deeper into nuanced feature processing. They efficiently combined user and item data, scaling up to meet the demands of large, real-time systems.

Here are the most known examples of neural models:
- Shallow and Deep Models: Imagine a world where opposites not only attract but also collaborate to create something groundbreaking. This is precisely what happened with the emergence of hybrid models, which ingeniously combine shallow (linear) learning architectures with deep (non-linear) ones. These models, such as the Wide&Deep model and its inventive variants like Deep&Cross, DeepFM, and AFM, have significantly enhanced recommendation systems by leveraging the strengths of both approaches.
- Natural Language Processing (NLP) Inspired Models: The world of NLP has lent some of its most innovative techniques to recommendation systems, transforming them in the process. Attention mechanisms, like those used in DIN, and sequence models, as seen in DIEN, have markedly improved the relevance and accuracy of recommendations. Moreover, the success of Transformer models in NLP has inspired adaptations for sequential recommendation tasks, leading to breakthroughs such as BERT4Rec and SSE-PT.
- Deep Reinforcement Learning: In a dynamic digital environment, staying static means falling behind. Recognizing this, deep reinforcement learning models have introduced an adaptive approach, continuously learning and evolving based on real-time user behavior. These models balance exploration with exploitation, constantly refining recommendations to align with ever-changing user preferences.
- Graph Neural Networks: The internet's complex web of relationships, from social networks to user-item bipartite graphs, is a treasure trove for recommendation systems. Graph neural networks have been pivotal in extracting valuable insights from these intricate structures, enhancing the precision, diversity, and explainability of recommendations.
- Causality-Inspired Methods: The recent shift towards understanding causality, rather than merely mapping associations, marks a significant evolution in recommendation systems. Causal inference methods offer a more holistic view, tackling challenges like bias, transparency, fairness, and robustness. These methods don't just predict; they explore new scenarios through interventions and counterfactual learning.
These traditional approaches have been pivotal in accurately and efficiently capturing user preferences. For those interested in a deeper dive into the history of recommendation systems, this comprehensive review is a treasure trove of information. But the journey of innovation is far from over. Let's turn our gaze to what the future holds in this exciting field.
LLM Implementations on Recommendation Systems
The capabilities of Large Language Models (LLMs) have indeed left us in awe, particularly their adeptness at understanding our preferences and needs in a variety of applications, ranging from knowledge retrieval to content curation. Consider the widespread adoption of ChatGPT, which has emerged as an indispensable tool in various tasks. Concurrently, the emergence of prompt engineering has highlighted our evolving interaction with LLMs like GPT, teaching us to elicit more nuanced responses through expertly crafted prompts. This significant paradigm shift opens up vast potential for recommendation systems.
It's noteworthy how teams at leading companies such as Microsoft and Google are pioneering in this space, applying LLMs in groundbreaking ways that are transforming the landscape of recommender systems. Their research and practical implementations, which we will explore in the upcoming sections, offer invaluable insights and foresight into the future of LLMs in shaping recommendation systems
Harnessing LLMs for Contextual Understanding
One of the cornerstones of effective recommendation systems is the ability to accurately capture user intent and context. This is where LLM-based models truly shine. Unlike traditional recommendation systems that primarily rely on user and item attributes, LLM-based models excel in grasping the subtleties of contextual information. They adeptly interpret user queries, item descriptions, and other textual data, offering a richer, more nuanced understanding of user preferences. This advanced capability allows them to tailor recommendations to each user's unique perspective, rather than relying on generalized predictions based on similar attributes.
The versatility of LLMs extends to their integration within existing recommendation frameworks. As discussed in the previous section, recommendation systems are often an amalgam of various features, including embeddings. The paper “A Survey on Large Language Models for Recommendation” sheds light on three distinct methodologies for incorporating LLMs into recommendation systems:
LLM Embeddings + RS: This modeling paradigm views the language model as a feature extractor, which feeds the features of items and users into LLMs and outputs corre- sponding embeddings. A traditional RS model can utilize knowledge-aware embeddings for various recommendation tasks.
LLM Tokens + RS: Similar to the former method, this approach generates tokens based on the inputted items’ and users’ features. The generated tokens capture potential preferences through semantic mining, which can be integrated into the decision-making process of a recommendation system.
LLM as RS*: Different from (1) and (2), this paradigm aims to directly transfer pre-trained LLM into a power ful recommendation system. The input sequence usually consists of the profile description, behavior prompt, and task instruction. The output sequence is expected to offer a reasonable recommendation result.

By leveraging the strengths of LLMs, recommendation systems can achieve a level of personalization and context-awareness previously unattainable. Let’s explore how this integration might reshape the landscape of personalized recommendations.
LLM as Recommender
To see LLMs in action, you can start by simply incorporating user preferences directly into your prompt. This approach allows you to request tailored recommendations with ease. Below is a practical example built using Langchain:
prompt = HumanMessage(
content=""" I am seeking for a sci-fi movie with a futuristic approach.
Could you recommend three? Output the titles only. Do not include other text."""
)
```
- Blade Runner 2049
- Ex Machina
- The Matrix
In our next example, we'll take a different approach: instead of defining a specific theme, we'll integrate past user actions into the prompt. This method demonstrates how dynamically adapting recommendations based on user behavior can yield diverse and relevant suggestions
prompt = HumanMessage(
content=""" Last week I have watched the following movies:
"Shawshank Redemption",
“The Godfather”
Can you recommend me another movie for tonight?
"""
)
```
`Based on your previous movie choices, here are three new movie recommendations for you:
- "Pulp Fiction"
- "Fight Club"
- "Goodfellas"`
Both of these responses are quite impressive. It's particularly fascinating to consider how simply fine-tuning our prompts can significantly enhance the effectiveness of LLMs. This potential positions them as likely frontrunners in the realm of recommender systems in the near future. However, when it comes to deploying these models in a production environment, there are additional considerations to address.
One key limitation is that LLMs typically base their recommendations on the data they were trained on, which may not directly align with the specific needs of your application. This is where the concept of Retrieval Augmented Generation (RAG) becomes crucial. RAG allows us to direct LLMs to make recommendations from a tailored dataset, effectively customizing their output to suit specific applications.
To further demonstrate the practical application of these concepts, let's delve into another example. For this, again I employed tools such as Langchain, Pinecone, and OpenAI to develop a unique chat agent. This agent is specifically designed to suggest movie recommendations from a handpicked selection of 1,000 titles.
Here's how it operates: When you request movie recommendations, the agent initially employs Retrieval Augmented Generation (RAG) to interpret your prompt. This interpretation is key to identifying the most relevant movie candidates from our dataset, which we have previously uploaded to Pinecone in the form of vectorized data. The agent then presents these selected candidates to GPT, incorporating them as contextual input. This step is crucial as it allows the GPT model to generate personalized movie suggestions based on the context derived from your initial prompt. The result is a finely-tuned recommendation that reflects your specific preferences and interests
Let's see the results!
#Instructing the LLM
messages = [
SystemMessage(content="You are a movie recommender.")
]
#Requesting for recommendations
query = "Can you recommend me some drama movies?"
augmented_prompt = f"""Answer the query only by referencing the context below.
Contexts:
{source_knowledge}
Query: {query}"""
Based on the given context, I recommend the following drama movies:
- Chang: A Drama of the Wilderness - a movie about a family's lives being disrupted by elephants in the jungles of Northern Siam.
- My Best Girl - a movie about a department store stock girl falling in love with a co-worker, despite him being engaged.
- Sumerki zhenskoy dushi - a movie about a young, rich woman dedicating her life to helping the poor, but facing a tragic incident that changes her life.
- A Woman of Paris: A Drama of Fate - a movie about a kept woman who runs into her former fiancé and is torn between love and comfort.`
(You can access the complete code for this setup in the provided colab document.)
With a well-structured Retrieval Augmented Generation (RAG) pipeline in place, leveraging LLMs as the backbone of a recommender system emerges as an efficient, accurate, and surprisingly straightforward approach to building personalization. An additional key advantage here is the ease of fine-tuning.

While it's possible to fine-tune the language model itself(parameters) for a specific task like movie recommendation, we can achieve significant enhancements in performance with less effort and cost by simply refining prompts, context and instructions. Therefore, iterating LLM recommenders is far less time-consuming than iterating through thousands of features in traditional recommender systems.
Now, let's examine the different types of fine-tuning possibilities that can be applied in our example.
Fine-Tuning the Instruction
In this part, we focus on defining the main purpose of the LLM. Providing precise instructions can notably influence the responses from the LLM. For instance, in our example, we instructed the LLM to act as a movie recommender. We can iterate this by introducing characteristics, such as adopting the language of an intellectual friend or a movie critic. Additionally, we can inject bias into the responses, like promoting a specific movie by instructing the LLM to show a preference for it.

Moreover, as previously mentioned, LLMs can handle various tasks within a recommendation system. A unified architecture for multiple tasks, like P5, demonstrates this versatility. P5 is designed to assist users with five different sets of tasks including rating prediction, sequential recommendation, explanation generation, review-related tasks, and direct recommendation.

Fine-Tuning the Prompt
The prompt is where we define the task and hand it over to the LLM, along with the context and query—comprising previous user interactions and users’ prompts in our case. By fine-tuning the prompt, we enhance how the LLM approaches the context and uses it to fulfill the users’ needs.

Fine-Tuning the Context
In our example, we provide the LLM with the user's previous interactions as context. A possible iteration in this regard is to include applied examples of similar tasks within the context. This method, known as In-context learning, is a specific form of prompt engineering where demonstrations of the task are provided to the model as part of the prompt, enabling the LLM to make more accurate recommendations.

As we have seen, the art of fine-tuning LLMs – whether it's through refining the instructions, the prompts, the context or the LLM itself– opens up a world of possibilities in creating more intuitive and responsive recommendation systems. These adaptations allow us to tailor the LLM's capabilities to specific needs and preferences, enhancing the overall user experience. However, the journey towards an optimal recommendation system doesn't stop at mere customization. Now, let us shift our focus to the pinnacle of personalized recommendation systems: crafting experiences in real-time.
Real-Time, Production Level, and Simplified.
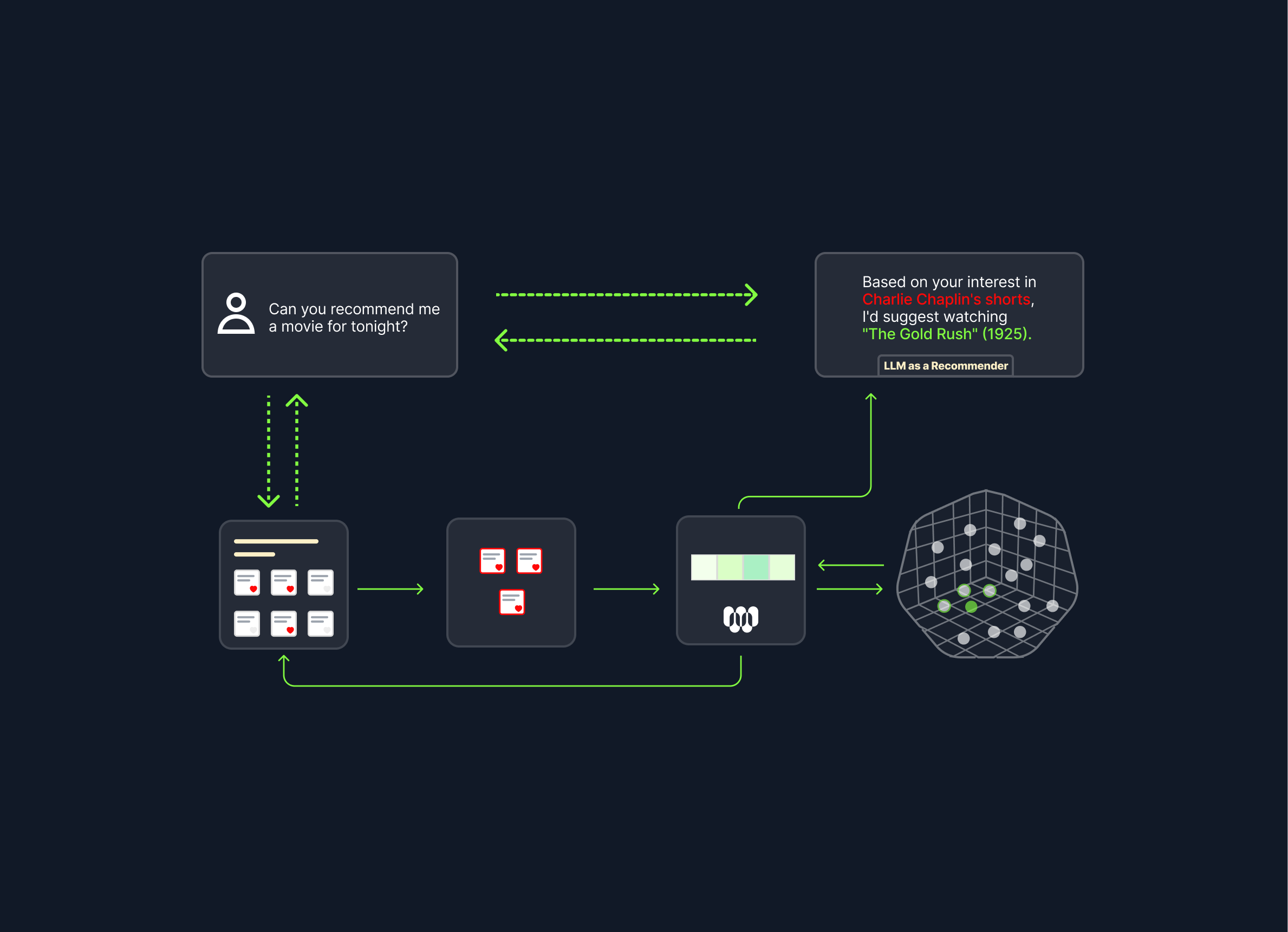
The magic of personalization truly comes alive when it's instantaneous—reshaping the user experience with each interaction to reflect the user's most recent preferences and actions. Achieving this level of real-time adaptation necessitates a seamless integration of user interactions into the LLM, which we have demonstrated through carefully crafted prompts. At this juncture, FirstBatch's User Embeddings play a pivotal role. They are adept at capturing user interactions in real-time and converting them into a format that can be directly fed into our LLM-based recommender system. This process enables the delivery of personalized content to users with remarkable efficiency and virtually no latency. Here's an outline of the essential pipeline to achieve this:
- Real-Time Interaction Capture: This involves monitoring user activities as they occur, ensuring that every action contributes to the personalization process.
- Interaction-Based Embedding Generation: Transforming these interactions into embeddings provides the necessary context for LLMs.
- RAG-Enhanced Item Retrieval: By applying RAG, bringing relevant items from a specific dataset into the recommendation context.
- Contextualized LLM Recommendations: Finally, feeding these context-rich inputs into the LLM, soliciting tailored recommendations.
We have covered the last two steps previously but how are we going to handle the first two, especially in production? This is where 'User Embeddings' comes into play. To demonstrate this in action, I present an example application that offers real-time personalized movie recommendations powered entirely by an LLM. Experience it firsthand here: Personalized Movie Recommender.
In this demo, your interactions with movies refine the recommendations you receive from the chat agent in real time with the help of FirstBatch SDK. Moreover, you can engage in conversations about your preferences, such as requesting jokes or stories.
For a deeper understanding of this demo, here are the steps we followed:
- Sourcing a dataset of 48,000 movies (utilizing the first 1,000 movies).
- Generating embeddings from movie descriptions using OpenAI's text-embedding-ada-002.
- Storing these embeddings in Pinecone.
- Creating a chat agent with GPT via Langchain.
- Capturing user interactions using FirstBatch SDK to generate User Embeddings.
- Shaping recommendations with an algorithm developed using User Embeddings Dashboard.
- Developing the application by adapting another Streamlit app.
Explore more about this demo and learn how to build your own: GitHub Repository for Personalized Movie Recommender.
Or, check out a similar application, a personalized news agent, developed by Anıl Berk Altuner: Personalized News Agent on GitHub.
For further reading on diverse applications of LLMs in recommender systems, consider these recent publications:
Augmenting recommendation systems with LLMs
A Survey on Large Language Models for Recommendation
Enhancing Recommendation Systems with Large Language Models
Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations